The boring parts of computer vision
I spend maybe 20% of my time working on the cool stuff: training models, custom algorithms, implementing clever tricks. The other 80% is labeling, backups, validation, and all the glue needed to turn it into a product. Even those “boring” parts have interesting sides to them.
Labeling, labeling, and.. labeling!
We process youth football games. There’s no public dataset for this. SoccerNet exists, but it’s all broadcast footage — professional cameras, consistent angles, high resolution. Our games come from fixed cameras on amateur fields, filmed by different providers like Veo, USF, and a sporadic enthusiastic parent on the sidelines. All look different, a model trained on one often fails on another.
So we label a lot of our own data.
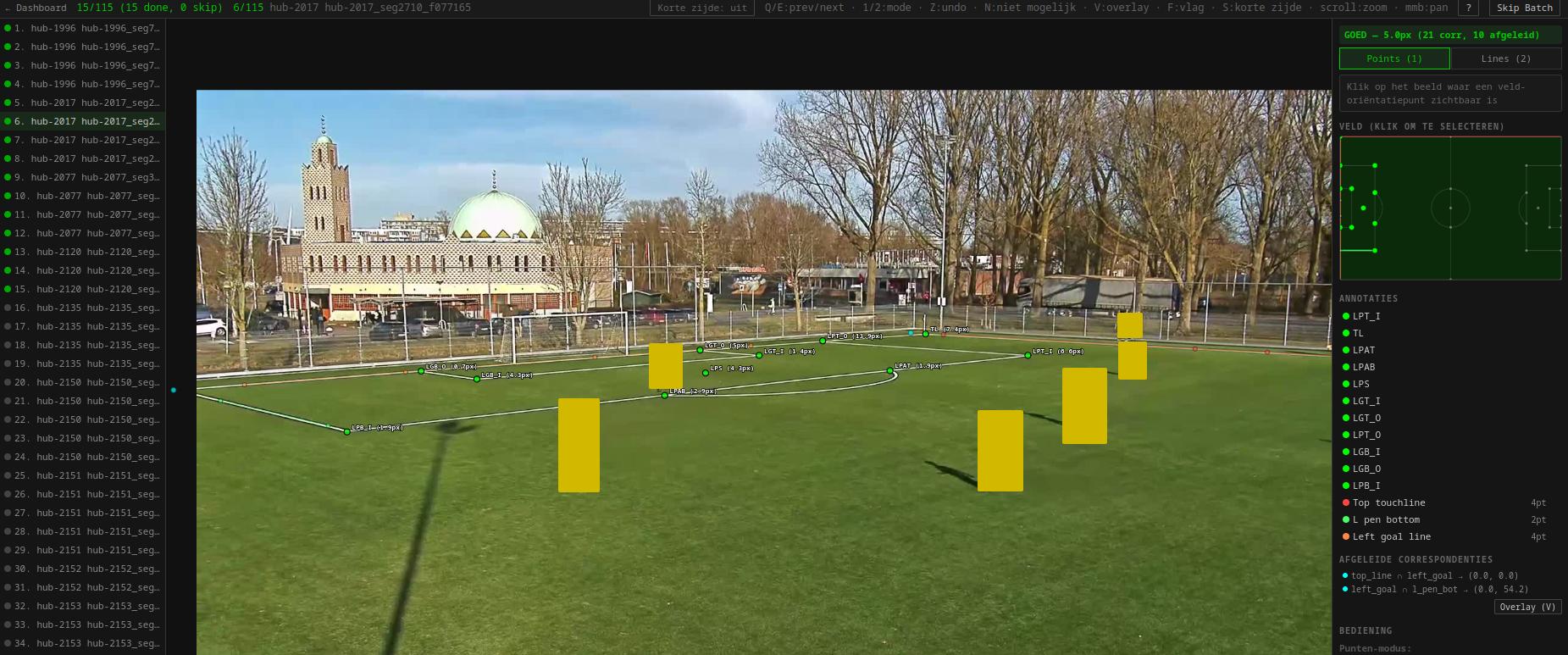
We started with open-source labeling tools. Label Studio gets maybe 80% of the way, but there’s always a fight with setup, and they never quite fit the workflow. Our labeling tasks are pretty varied, ranging from “where is the ball” (my girlfriend actually finds this a fun task) to field calibration.
So we built our own labeling web app. We attempted this a year and a half ago, back then it took around 4-5 days to get something solidly working. Coding LLMs make life easy nowadays, especially with these independent side projects. The whole thing took around a day, from a local tryout to a deployed multi annotator tool. Most time is actually spent trying to define exactly what we want to label. “Where is the ball” sounds easy, but there is a surprising amount of edge cases. 2 balls on the field. The referee holding the ball. The ball in play but completely (or 85%, or 60%) obscured by a player. The kind of detail nobody ever wants to think about, I certainly did not.
My initial idea was to find some people in my own network to help out with labeling; the idea being that knowing someone gives more consistent quality. This works reasonably well, but lacks a bit of iteration speed, so I went to Upwork, which works better than I expected. “Managing” those relationships takes time; onboarding, writing clear instructions, checking their output, giving feedback. All in all it might take 2-3 hours to find someone and get them up and running over the course of a week or 2.
Then the loop continues: models are fine-tuned with new data, deployed to production, and 2 weeks later we can generate new datasets from all edge cases that occurred.
Quality checking with metrics, not dashboards
Did we correctly detect the ball in this game? Did player detection degrade after the last deploy? Questions that are usually answered by ML observability tools. Tried 2 or 3 of them, but found them either to be cumbersome to set up and maintain, or not answer the questions we were having.
Being a developer, the natural answer was obvious: build a complete new thing! Some few days later (this was the copy-paste-to-openrouter instead of claude code era), a beautiful web dashboard was born. It displayed diagnostic images from every pipeline step, for every game. A magical garden of truth, our golden beacon of quality. I never looked at it.
It turned out to be exactly the wrong thing. Heinrich Hartmann (Zalando) has a great talk about this. One of the lessons for me; don’t build something to look at all day, only to inform you once something goes wrong. Well set alerts on key metrics are worth more than the best dashboards.
So that’s what we do. Every step in our pipeline dumps metrics into its log output, and into a structured database. We might log things like
010_frames done | 40.4s | 15050 frames
020_camera_calibration done | 83.8s | 88.8% calibrated, median reproj 0.86m
035_ball_detect done | 34.2s | 93% det rate
060_track done | 12.0s | 1221 tracks | avg 274.3 det/track | balance 97.1% | ARI 0.831
080_core_id done | 5.6s | 1221 tracks | 240/1221 assigned (20%)
Segment complete: 16 steps, 525.9s total
A single game that has 100k detections in one team and 900k in the other? A game where we only succeeded in 60% of the frames to detect a reasonably looking soccer field? Those are the kind of alerts I’d like to get, and are a good reason to dive into a game. A web UI seemed great, but a single command line to sync the whole game to a dev box is almost as quick, and had the advantage that I can directly go to work. Sometimes it’s a bug (or an actual bug on the camera), sometimes a weird camera angle, or a volleyball game that slipped through.
On rainy Fridays, I snuggle down with a cup of tea and do what humanity is made to do: scan through logs of hundreds of games. Every game and segment has “health diagnostics”: core metrics that try to summarize how stable a step ran. We can prod those statistically (what are the ourliers), or ask open questions to our favourite tool calling LLMs; “which games last week had unusually metrics?”. The latter certainly doesn’t catch everything, but it certainly saves a lot of work.
The obvious downside: this is all manual. If I deploy a new version and don’t actively check the metrics, nobody (other than end users) will tell me something broke. There’s no alert that fires when algorithm quality drops in a non-obvious way. With a team of our size (me!) that’s the tradeoff, and honestly, a fine one if you ask me.

Datasets & backups
Backups are like fire extinguishers: a burden that nobody cares about until there is a big oopsie (with your frying pan or a rm -f). Our datasets (18 at this point) range from some MB to around 100GB. Not huge by ML standards, but they consist of millions of small images. That’s where managing and backing up these files gets annoying.
The obvious choice to manage datasets is DVC, which works well for moderately sized datasets with larger files. Some of our datasets, however, have millions of images, which DVC really doesn’t like. The hashing alone takes forever, and our setup doesn’t really need full version control over individual images anyway.
I also looked at tools that pack images into a single datastore: HDF5, pytorch-lmdb. They solve the small-files problem, but plain files on disk are just convenient. It’s easy to remove a few bad apples, do a quick visual check, or write a tiny Python script. Normal Linux tools can handle most of the ad hoc changes you might want, and all of that convenience is lost once everything lives inside blob storage. TurboJPEG and optimized GPU JPEG loading already make these datasets fast enough not to be the bottleneck in training.
So what we actually do is simpler. For a task like ball detection, we have multiple raw sources: SoccerNet, SoccerTrack, plus our own labeled data. Each lives in its own directory, with whatever format it came in. Then we have a build step that unifies all of these into a versioned, ready-to-train dataset: same label format, same directory structure, consistent train/val/test splits, with some basic sanity checks baked in. A new version means a new snapshot, not a diff.
Backups are a thin wrapper that gzips each dataset (raw or built) into a single file and uploads it to S3. Syncing between dev machines is just rsync. The whole thing is less than 300 lines of Python and works smoothly. Classic and boring.
Building AI
Building AI is fun, and cooler now than it was 5 years ago. What makes it an actual product is not the fancy part. Like most things, once you spend time on them, they become interesting in their own right. The boring 80% turns out to be almost as fun as building the models. Just don’t expect anyone at a birthday party to care about your backup strategy.